年前项目中有个需求需要用到关系型数据库,因为某些原因需要自己写封装类操作Sqlite,当时主要仿写于FMDB,现在再回头读读源码;
简介
FMDB是一个SQLite的OC包装器;(最新的版本是2.7.5)
主要的类:
- FMDatabase - 为一个SQLite数据库,用来执行SQL语句;
- FMResultSet - 为FMDatabase执行查询语句时的结果集;(next方法取值方式让人想起NSEnumerator)
- FMDatabaseQueue - 用于多线程操作数据库读写时保证线程安全的串行队列(对FMDatabaseQueue方法的调用是阻塞的)
- FMDatabaseAdditions - 为FMDatabase的分类,提供一些便利方法
- FMDatabasePool - 为FMDatabase对象池(使用于只对型数据库,不然容易产生死锁)
必备的文件是FMDatabase类,其他的都是副产品;
基本使用方式
- 创建
根据初始化方法传入参数的不同,分三种情况: 传入正常的文件路径,则正常创建数据库; 如果传入的路径是空字符串,则创建数据库的位置在temp文件夹下,关闭连接时,数据库会被删除;传入NULL,创建基于内存的数据库,关闭连接时会被销毁;
- 打开/关闭
- 执行更新和查询操作 FMDatabase.h中有提供-lastErrorMessage和-lastErrorCode方法,可以检索更多相关错误信息;
瞄了一眼readme的Support/License,虽然是MIT许可证,可能是本人理解能力有限,感觉有点不爽,以前听个前辈说他们的SDK是购买的,也许也是有一定道理的;当然浓浓的傲慢在开头的Contributing已跃然纸上,而不是幽默;
SQLite的架构
翻译一下官网的文档
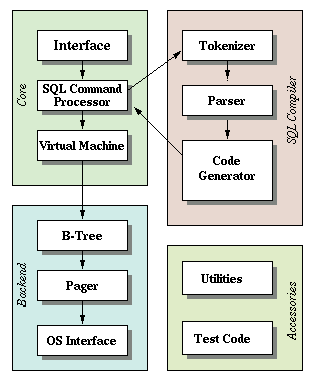
SQLite的工作原理是将SQL文本编译为字节码,然后使用虚拟机运行该字节码。sqlite3_prepare_v2()和相关接口充当将SQL文本转换成字节码的编译器。sqlite3_stmt对象是单个字节代码的容器,用来实现单个SQL语句。sqlite3_step()接口将字节码程序传递到虚拟机中,并运行该程序,直到执行完成、或形成需要返回的结果行、或遇到严重错误、或被中断。
接口
大部分C语言接口位于源文件main.c、legacy.c和vdbeapi.c中,尽管某些例程分散在其他文件中,但是可以在文件作用域中访问相关数据结构。sqlite3_get_table()例程在table.c中实现。sqlite_mprinf()例程可以在prinf.c中找到。sqlite3_complete()接口在complete.c中。TCL接口在tclsqlite.c中实现。
为了避免名称冲突,SQLite库中所有外部符号都以sqlite3前缀开头。那些供外部使用的符号(即构成SQLite API的符号)会添加下划线,因此以sqlite3开头。扩展API有时会在下划线之前添加扩展名(例如:sqlite3rbu_或sqlite3session)。
令牌解析器/标记分析器(Tokenizer)
当计算包含SQL语句的字符串时首先会发送到标记分析器。标记分析器会将SQL文本分解为很多标记,然后逐个交给解析器。标记分析器位于tokenize.c中手工编码。
注意此设计,标记分析器程序调用解析器。大家更熟悉YACC和BISON可能习惯于做相反的事情,让解析器调用标记分析器。但是,让标记分析器调用解析器更好一点,因为他使线程更安全,运行速度更快;
解析器(Parser)
解析器根据标记/令牌的上下文解释其意义。SQLite的解析器是使用Lemon解析器生成器生成。Lemon执行与YACC/BISON相同的工作,但不同之处是,使用更少的产生错误的语法输入方式。Lemon还生成了一个解析器,它是可重入和线程安全的。Lemon还定义了非终端析构函数的概念,以便在遇到语法错误时不产生内存泄露。在parse.y中可以见到驱动Lemon和定义SQLite可以理解的SQL语言的语法文件。
因为Lemon是开发机上不常用的程序,因此完整源码可见于SQLite分发版tool子目录下。
代码生成器(Code Generator)
在解析器将令牌组装到一个解析树后,代码生成器将运行以分析解析树并生成执行SQL语句工作的字节码。准备好的语句对象是这个字节码的容器。
代码生成器包含很多文件,有attach.c, auth.c, build.c, delete.c, expr.c, insert.c, pragma.c, select.c, trigger.c, update.c, vacuum.c, where.c, wherecode.c, and whereexpr.c.大部分神奇的魔法在这些文件中产生。
expr.c处理表达式的代码生成。where*.c处理SELECT、UPDATE、DELETE语句上的WHERE子语句的代码生成。
attach.c, delete.c, insert.c, select.c, trigger.c update.c, vacuum.c 处理具有相同名称的SQL语句的代码生成。(每个文件调用expr.c中的例程,必要时调用where.c中例程)
其他的SQL语句编码为build.c。auth.c文件中实现sqlite3_set_authorizer()的功能。
代码生成器,尤其是位于where*.c和select.c中的逻辑有时被称为查询规划器。对于任何特定的SQL语句,可能有成百上千种不同的算法去计算最后的答案。查询规划器是一个AI,它努力从这些数百万个选项中选择最佳的算法实现。
字节码引擎(Bytecode Engine)
代码生成器创建的字节码程序运行在虚拟机上。
虚拟机本身完全包含在单个源文件vdbe.c中。vdbeInt.h定义了虚拟机私有的结构和接口,vdbe.h头文件定义了虚拟机与剩余的SQLite库之间的接口。
各种其他的vdbe*.c文件是虚拟机的帮助器。
虚拟机和接口模块间其余部分用与构建VM程序需要的功能包含在vdbeaux.c中。
vdbeapi.c文件包含虚拟机的外部接口,比如sqlite3_bind_int() 和 sqlite3_step()。单个值(字符串、证书、浮点型、BLOBs)是存储在名为Mem的内部对象中,该对象实现在vdbemem.c中。
SQLite使用C语言例程的回调函数来实现SQL函数。即使是内建的SQL函数也是以这种方式实现的。大部分的SQL内建函数(如: abs(), count(), substr()等) 可以在func.c中找到。日期和时间转换函数在data.c文件中。某些函数(如 coalesce()和typeof())是由代码生成器直接作为字节码实现。
B树(B-Tree)
磁盘上维护的SQLite数据库是使用btree.c源文件中的B树实现的。数据库中的每个表和索引都使用单独的B树。所有的B树存储在同一个数据文件中。文件格式详细信息是稳定和定义良好的,并保证良好的向前兼容性。
页面缓存
B树模块以固定页面大小从磁盘请求信息。默认的页面大小为4096字节,也可以是512~65536字节间任意大小。页面缓存负责读取、写入、缓存这些页面。页面缓存还提供回滚和抽象的原子提交、并负责数据库文件的锁定。B树驱动程序从页面缓存请求特定页面,并当其想要修改页面或提交、回滚修改时通知页面缓存。页面缓存处理所有当复杂细节以确保快速、安全、高效的处理请求。
主页面缓存的实现位于pager.c中。WAL模式的逻辑位于wal.c中。内存缓存由pcache.c和pcache1.c文件实现。页面缓存子系统和剩余的SQLite之间的接口在头文件pager.h中定义。
操作系统接口
SQLite使用称为VFS抽象对象使其在不同操作系统之间提供可移植性。每个VFS对象都提供了磁盘的打开、关闭、读写文件方法,以及其他特定任务,比如查找当前时间、获取随机性以初始化内置伪随机数生成器。SQLite当前为unix(os_unix.c)和Windows(os_win.c)提供VFSes。
通用功能
内存申请,字符串无关对比例程,可移植的文本-数字转换例程及其他工具位于util.c中。
解析器使用的符号表维护在哈希表中,见于hash.c中。
utf.c文件包含Unicode转换子例程。
SQLite对于prinft()及其扩展、伪随机数生成器(RPNG)有自己的实现,分别在printf.c与random.c中。
测试代码
源文件目录中在src/文件夹下以test开头的文件仅仅用于测试,并不包含在标准构建的库中。
SQLite C/C++ 接口简介
人肉翻译自官网
-
概述
以下两个对象和八种方法构成了SQLite接口的基本元素:
- sqlite3 数据库连接对象。由sqlite3_open()创建连接,由sqlite3_close()销毁连接。
- sqlite3_stmt 准备好的语句对象。通过sqlite3_prepare()创建,通过sqlite3_finalize()销毁。
- sqlite3_open() 从一个新的或现有的SQLite数据库打开一个连接。sqlite3的构造函数。
- sqlite3_prepare() 将SQL文本编译为字节码,用于查询或更新数据库。是sqlite_stmt的构造函数。
- sqlite3_bind() 将应用程序数据存储到原始SQL的参数中。
- sqlite3_step() 将sqlite3_stmt前进到下一个结果行或完成操作。
- sqlite3_column() sqlite3_stmt的当前结果行中的列的值。
- sqlite3_finalize() sqlite3_stmt的析构函数。
- sqlite3_close() sqlite3的析构函数。
- sqlite3_exec() 用于字符串型一个或多个SQL语句的包装函数,该函数执行sqlite3_prepare()、sqlite3_step()、sqlite3_column()、sqlite3_finalize()。
-
核心对象和接口
一个SQL数据库引擎的主要任务是计算SQL语句。因此,开发人员需要两个对象:sqlite3、sqlite3_stmt。
例程列表是概念性的,而不是实际的。这些例程中有许多不同的版本。
-
核心例程和对象的典型用户
要运行SQL语句,应用程序需要执行以下步骤:
- 使用sqlite3_prepared()创建准备好的语句。
- 通过调用sqlite3_step()一次或多次来运行准备好的语句。
- 对于查询,通过在两个调用sqlite3_step()之间调用sqlite3_colunm()来提取结果。
- 使用sqlite3_finalize()销毁准备好的语句。
以上是所有真正需要知道的,以便有效地使用SQLite。剩下的都是优化和细节了。
如何直接使用SQLite?
SQLCipher是什么?
学到的新知识
- strtoul 将 2.7.5 字符串 -> 0x0275 便于版本对比,不过我一般用其他方法compare
char *e = nil; FMDBVersionVal = (int) strtoul([junk UTF8String], &e, 16); - 创建In-Memory数据库只要传入:memory:参数作为文件名,每一个:memory:数据库都是独立的;
rc = sqlite3_open("file::memory:?cache=shared", &db); rc = sqlite3_open("file:memdb1?mode=memory&cache=shared", &db);如果同个进程中使用URI名称方式打开In-memory数据库允许多个共享缓存;以空字符串名称可打开临时数据库,与内存型数据库差别不大,只有面临内存压力时,才将临时数据库的部分数据刷新到磁盘上;
- FTS3(full-text search),SQLite虚拟表模块,允许用户对一组文档进行全文检索;